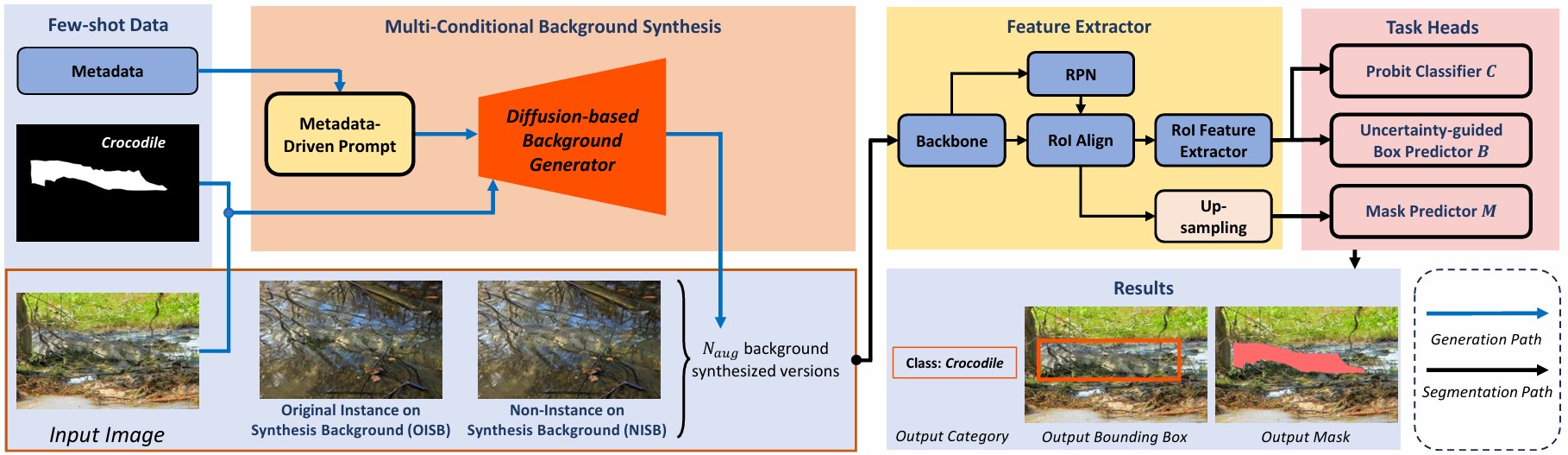
Camouflage object detection and instance segmentation remain a challenging frontier in
computer vision due to the intrinsic high similarity between foreground objects and their background
surroundings. Furthermore, the scarcity of annotated camouflage data exacerbates the difficulty of
training robust models, particularly in data-sparse regimes. In this paper, we introduce CAMO-InstSynth,
a novel data enhancement framework exploiting the background context understanding to address few-shot
camouflage object detection and instance segmentation. Accordingly, we propose a Multi-Conditional
Background Synthesis Module that utilizes diffusion models to generate diverse, highfidelity backgrounds
that maintain semantic consistency with camouflaged foregrounds. Unlike traditional augmentation
techniques, which increase only the instance diversity, our method further conditions the synthesis
process to simulate the camouflage environment. We validate our approach on the common CAMO-FS dataset
over strong few-shot baselines. Our experiments demonstrate that CAMO-InstSynth significantly outperforms
state-of-the-art methods, improving the iFS-RCNN baseline in both Segmentation and Detection tasks.
Code
Presentation
Citation:
Thanh-Danh Nguyen, Vinh-Tiep Nguyen†, Kunpeng Li, and Tam V. Nguyen.
“CAMO-InstSynth: Few-shot Camouflage Instance Segmentation with Multi-Conditional Background
Synthesis and Generative Augmentation.”
18th Asian Conference on Intelligent Information and Database Systems, 2026.
[DOI,
PDF]
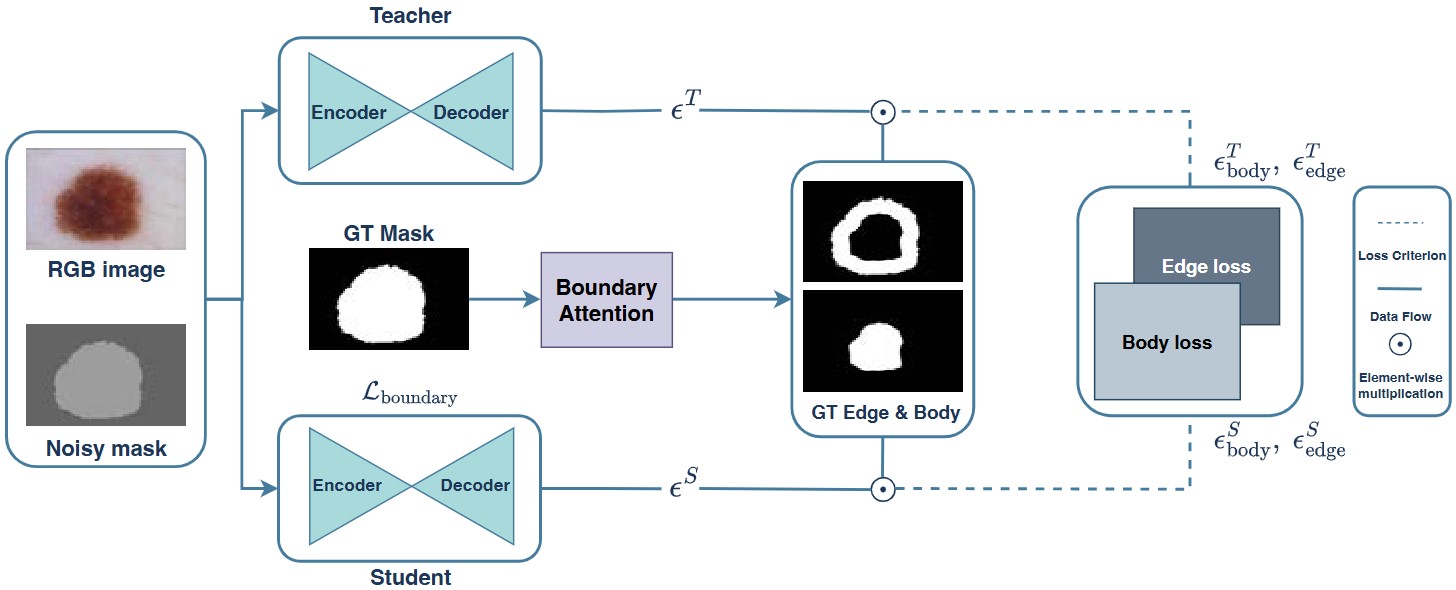
Accurate skin lesion segmentation is crucial for early melanoma detection and reliable
medical diagnosis. Recently, such generative diffusion-based segmentation models have achieved
state-of-the-art performance in this task. However, their large number of parameters hinders the
deployment in real-world clinical and mobile settings. A key challenge is how to compress these
models while preserving their reliability in diagnosis. To this end, we propose an edge-focused
knowledge distillation (EFKD) strategy for the generative diffusion-based skin lesion segmentation,
prioritizing contour information transfer from teacher to student. Accordingly, we introduce
Lite-DermoSegDiff, a lightweight diffusion-based lesion segmentation model that integrates knowledge
distillation with boundary-aware supervision. This design ensures that the student network
maintains sharp lesion boundaries while significantly reducing model parameters. Extensive
experiments on the common ISIC2018 and HAM10000 dermoscopic benchmarks demonstrate that our
method achieves up to 88.9% parameter reduction while maintaining competitive segmentation
accuracy. These results show that diffusion-based segmentation models can be substantially
compressed without compromising boundary awareness, paving the way for efficient and clinically
deployable solutions in resource-constrained environments.
Code
Citation:
Viet-Hoang Doan, Thanh-Danh Nguyen†, Tuan-Kiet Ngo, and Vinh-Tiep Nguyen.
“A Knowledge Distillation Approach for Diffusion-based Generative Skin Lesion Segmentation.”
2025 RIVF International Conference on Computing and Communication Technologies. IEEE, 2025. (Scopus)
[DOI,
PDF]
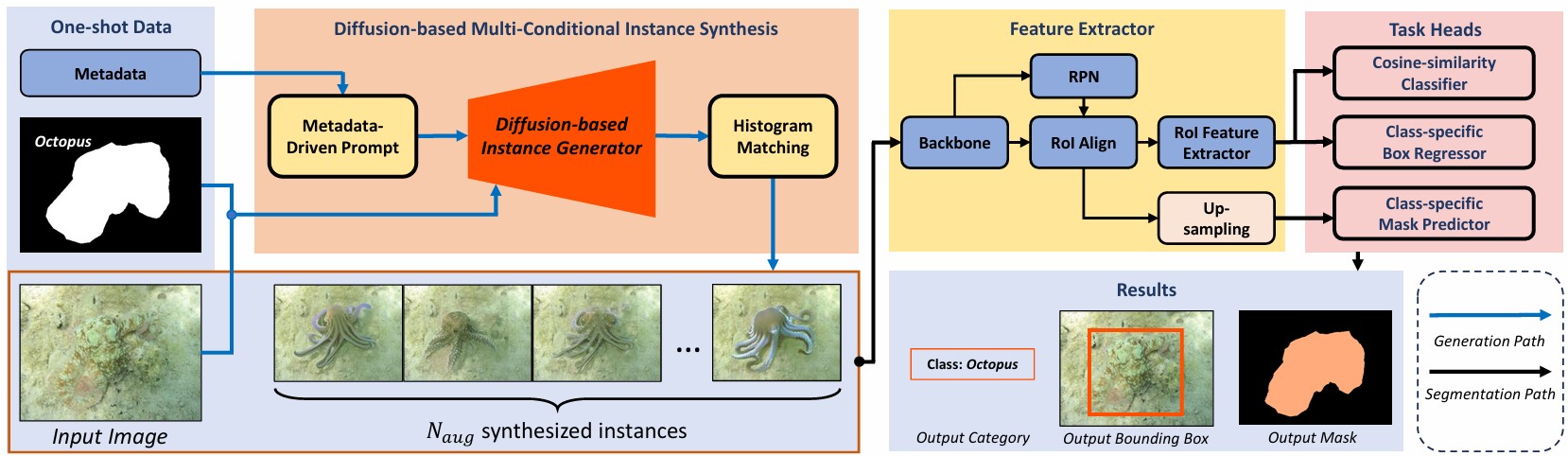
Identifying camouflaged instances is a critical yet underexplored problem in computer
vision, where traditional segmentation models often fail due to extreme visual similarity between
foreground and background. While recent advances have shown promise with deep learning models, they
heavily depend on large annotated datasets, which are costly and impractical to collect in camouflage
scenarios. In this work, we tackle this limitation by introducing a novel framework, dubbed CAMO GenOS,
that leverages one-shot annotated samples to drive a generative process for data enrichment. Our
approach integrates prompt-guided and mask-conditioned generative mechanisms to synthesize diverse,
high-fidelity camouflaged instances, thereby enhancing the learning capacity of segmentation models
under minimal supervision. We demonstrate the effectiveness of our CAMO-GenOS by setting up a novel
state-of-the-art baseline for one-shot camouflage instance segmentation research on the challenging
CAMO-FS benchmark.
Code
Poster
Presentation
Citation:
Thanh-Danh Nguyen, Vinh-Tiep Nguyen†, and Tam V. Nguyen
“Generative One-shot Camouflage Instance Segmentation.”
2025 International Conference on Multimedia Analysis and Pattern Recognition (MAPR). IEEE, 2025. (Scopus)
[DOI,
PDF]
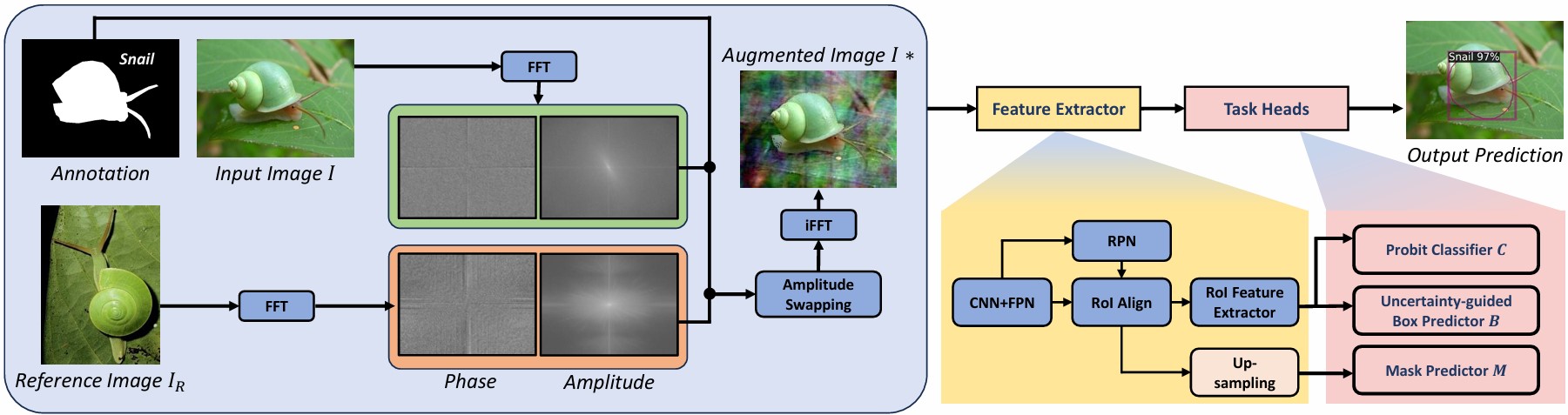
Few-shot instance segmentation is an intense yet essential task, particularly in camouflaged
scenarios where visual ambiguity between foreground and background makes instance level recognition more
difficult. Prior approaches primarily focused on image augmentations in the color space domain to provide
diverse perspective information to the segmentation models. However, this type of augmentation often fails
to capture the full range of visual characteristics needed for robust generalization, particularly in
camouflage images, due to the limited similar representation in the color space domain. To this end, we
tackle this gap by exploiting a novel approach to augment and enhance image features in the derivative
frequency domain. Accordingly, we propose a novel framework tailored for few-shot camouflage instance
segmentation via the instance-aware frequency-based augmentation, dubbed FS-CAMOFreq, to enhance image
diversity while preserving semantic structure, thereby improving the ability of the few-shot segmentor
to learn from limited data. Extensive experiments on the challenging CAMO-FS benchmark demonstrate that
our approach achieves superior performance compared to state-of-the-art baselines.
Code
Poster
Presentation
Citation:
Thanh-Danh Nguyen, Hung-Phu Cao, Thanh Duc Ngo, Vinh-Tiep Nguyen†, and Tam V. Nguyen,
“Few-Shot Instance Segmentation: An Exploration in the Frequency Domain for Camouflage Instances.”
2025 International Conference on Multimedia Analysis and Pattern Recognition (MAPR). IEEE, 2025. (Scopus)
[DOI,
PDF]
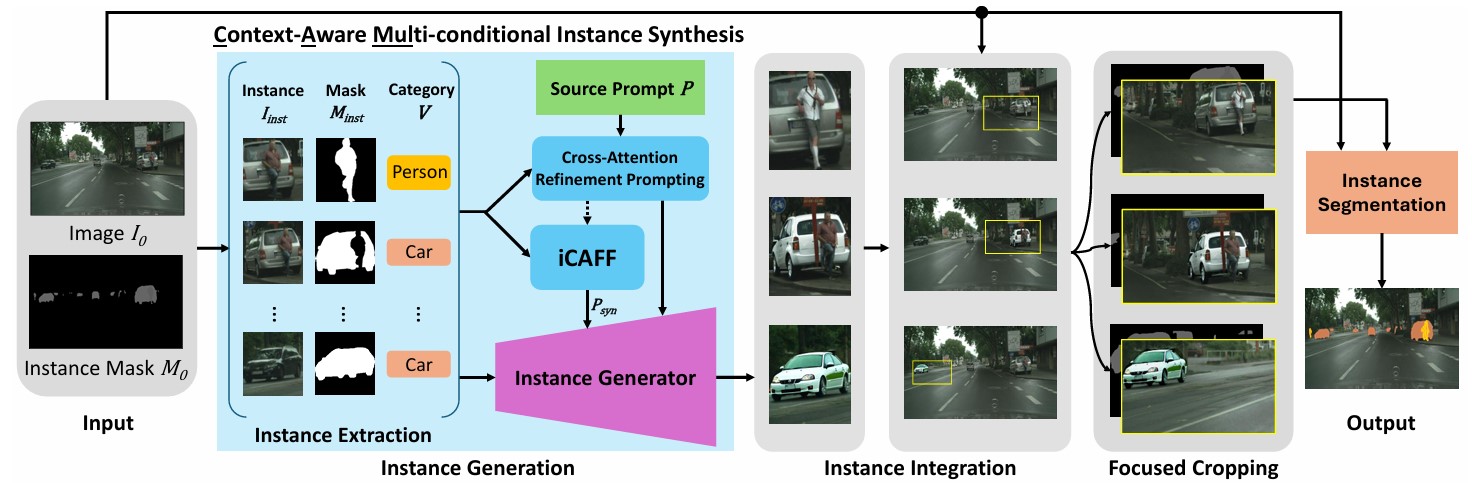
Instance image segmentation task requires training with abundant annotated data to achieve
high accuracy. Recently, conditional image synthesis has demonstrated its effectiveness in generating
synthetic data for this task. However, existing image synthesis models face challenges in generating target
instances to match the masks with complex shapes. Moreover, others fail to create diverse instances due to
utilizing low-context simple text prompts. To address these issues, we propose CAMUL, a framework for
context-aware multi-conditional instance synthesis. CAMUL introduces two key innovations: CARP
(cross-attention refinement prompting) to enhance the alignment of generated instances with conditional
masks, and iCAFF (incremental context-aware feature fusion) to determine the general embeddings of the
instances for a more precise context understanding. Our method significantly improves segmentation
performance, increasing up to 15.34% AP on Cityscapes and 3.34% AP on the large-scale ADE20K benchmark
compared to the baselines.
Code
Citation:
Thanh-Danh Nguyen, Trong-Tai Dam Vu, Bich-Nga Pham, Thanh Duc Ngo, Tam V. Nguyen, and Vinh-Tiep Nguyen†,
“CAMUL: Context-Aware Multi-conditional Instance Synthesis for Image Segmentation”,
IEEE MultiMedia, Jun 2025. IF = 3.3 (SCIE)
[DOI,
PDF]
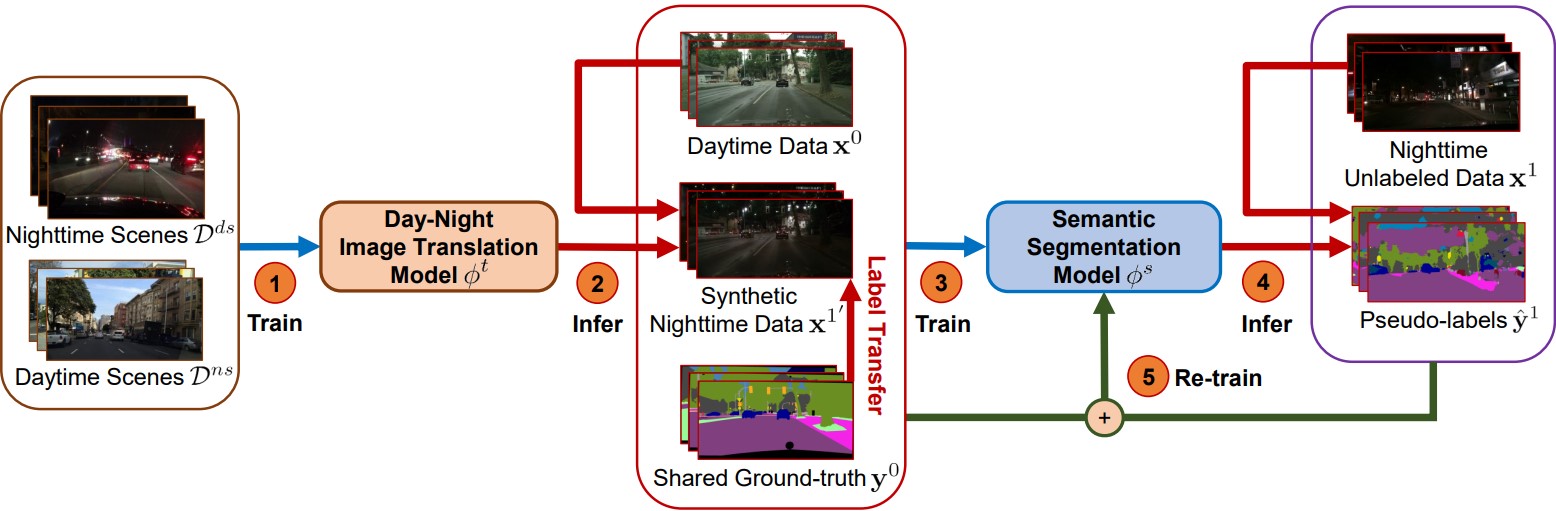
Semantic segmentation plays a crucial role in traffic scene understanding, especially in nighttime condition.
This paper tackles the task of semantic segmentation on nighttime scenes. The largest challenge of this task is the lack of
annotated nighttime images to train a deep learning-based scene parser. The existing annotated datasets are abundant in daytime
condition but scarce in nighttime due to the high cost. Thus, we propose a novel Label Transfer Scene Parser (LTSP) framework
for nighttime scene semantic segmentation by leveraging daytime annotation transfer. Our framework performs segmentation in
the dark without training on real nighttime annotated data. In particular, we propose translating daytime images to
nighttime condition to obtain more data with annotation in an efficient way. In addition, we utilize the pseudo-labels
inferred from unlabeled nighttime scenes to further train the scene parser. The novelty of our work is the ability to
perform nighttime segmentation via daytime annotated label and nighttime synthetic versions of the same set of images.
The extensive experiments demonstrate the improvement and efficiency of our scene parser over the state-of-the-art methods
with the similar semi-supervised approach on the benchmark of Nighttime Driving Test dataset. Notably, our proposed method
utilizes only one tenth of the amount of labeled and unlabeled data in comparison with the previous methods.
Code
Citation:
Thanh-Danh Nguyen, Nguyen Phan, Tam V. Nguyen†, Vinh-Tiep Nguyen, and Minh-Triet Tran,
“Nighttime Scene Understanding with Label Transfer Scene Parser”,
Image and Vision Computing, Sep 2024.
[DOI,
PDF]
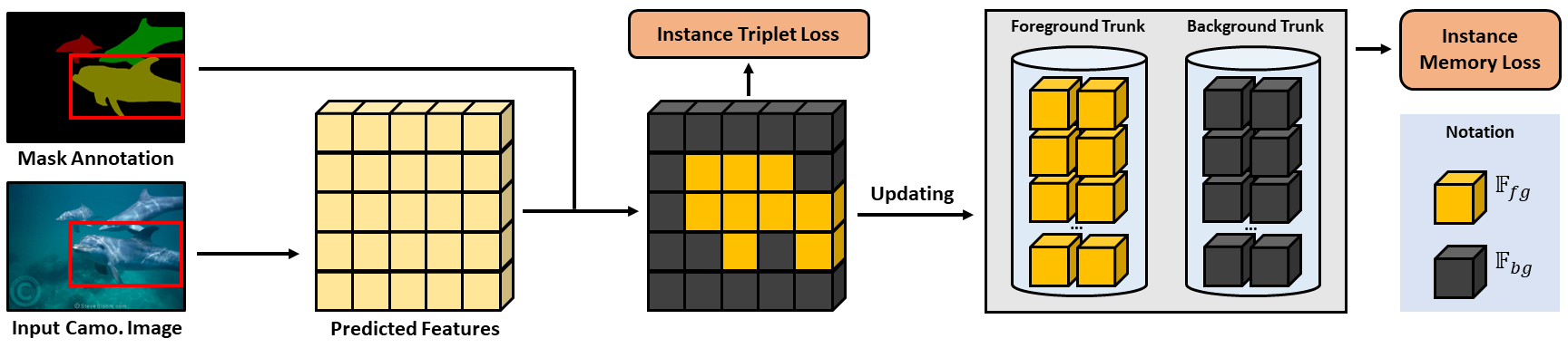
Camouflaged object detection and segmentation is a new and challenging research topic in computer vision.
There is a serious issue of lacking data on concealed objects such as camouflaged animals in natural scenes. In this paper,
we address the problem of few-shot learning for camouflaged object detection and segmentation. To this end, we first collect
a new dataset, CAMO-FS, for the benchmark. As camouflaged instances are challenging to recognize due to their similarity compared
to the surroundings, we guide our models to obtain camouflaged features that highly distinguish the instances from the background.
In this work, we propose FS-CDIS, a framework to efficiently detect and segment camouflaged instances via two loss functions
contributing to the training process. Firstly, the instance triplet loss with the characteristic of differentiating the anchor,
which is the mean of all camouflaged foreground points, and the background points are employed to work at the instance level.
Secondly, to consolidate the generalization at the class level, we present instance memory storage with the scope of storing
camouflaged features of the same category, allowing the model to capture further class-level information during the learning
process. The extensive experiments demonstrated that our proposed method achieves state-of-the-art performance on the newly
collected dataset.
Code
Dataset
Poster
Citation:
Thanh-Danh Nguyen*, Anh-Khoa Nguyen Vu*, Nhat-Duy Nguyen*, Vinh-Tiep Nguyen, Thanh Duc Ngo, Thanh-Toan Do,
Minh-Triet Tran, and Tam V. Nguyen†, “The Art of Camouflage: Few-shot Learning for Animal Detection and Segmentation”,
IEEE Access, Jul 2024. IF = 3.4 (SCIE)
[DOI,
ArXiv]
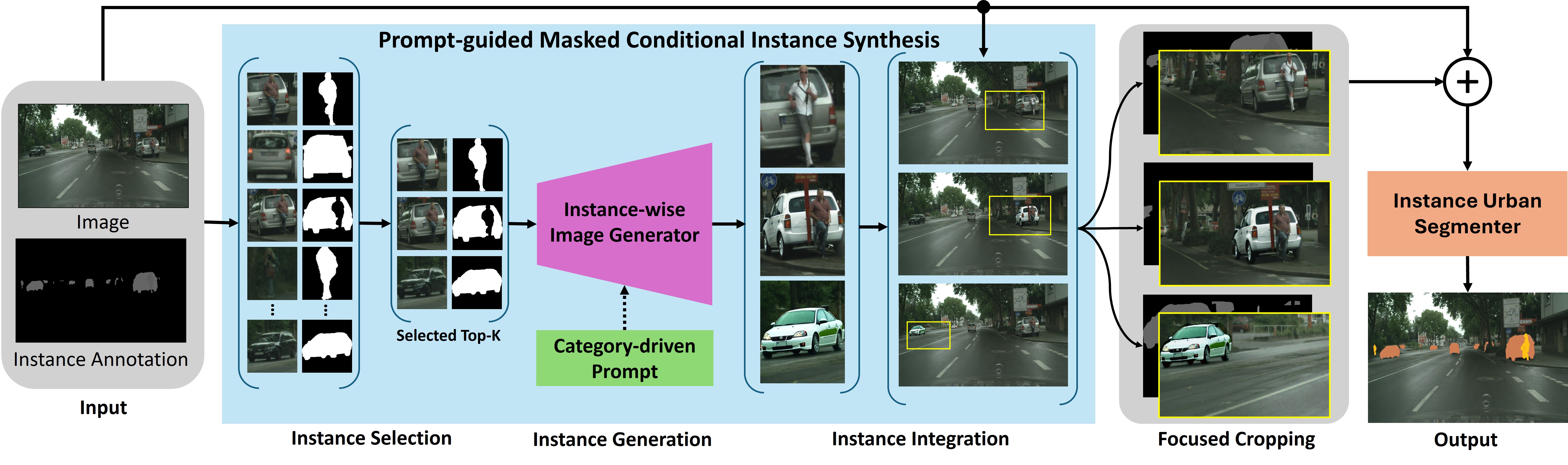
Scene understanding at the instance level is an essential task in computer vision to support modern
Advanced Driver Assistance Systems. Solutions have been proposed with abundant annotated training data. However, the annotation at
the instance level is high-cost due to huge manual efforts. In this work, we solve this problem by introducing
InstSynth, an advanced framework leveraging instance-wise annotations as conditions to enrich the training data.
Existing methods focused on semantic segmentation via using prompts to synthesize image-annotation pairs, facing
an unrealistic manner. Our proposals utilize the strength of such large generative models to synthesize instance
data with prompt-guided and maskbased mechanisms to boost the performance of the instancelevel scene understanding
models. We empirically improve the performance of the latest instance segmentation architectures of FastInst and
OneFormer by 14.49% and 11.59% AP, respectively, evaluated on the Cityscapes benchmark. Accordingly, we construct
an instance-level synthesized dataset, dubbed IS-Cityscapes, with over a 4× larger number of instances in comparison
with the vanilla Cityscapes.
Code
Poster
Presentation
Citation:
Thanh-Danh Nguyen, Bich-Nga Pham, Trong-Tai Dam Vu, Vinh-Tiep Nguyen†, Thanh Duc Ngo, and Tam V. Nguyen.
“InstSynth: Instance-wise Prompt-guided Style Masked Conditional Data Synthesis for Scene Understanding.”
2024 International Conference on Multimedia Analysis and Pattern Recognition (MAPR). IEEE, 2024. (Scopus)
[DOI,
PDF]
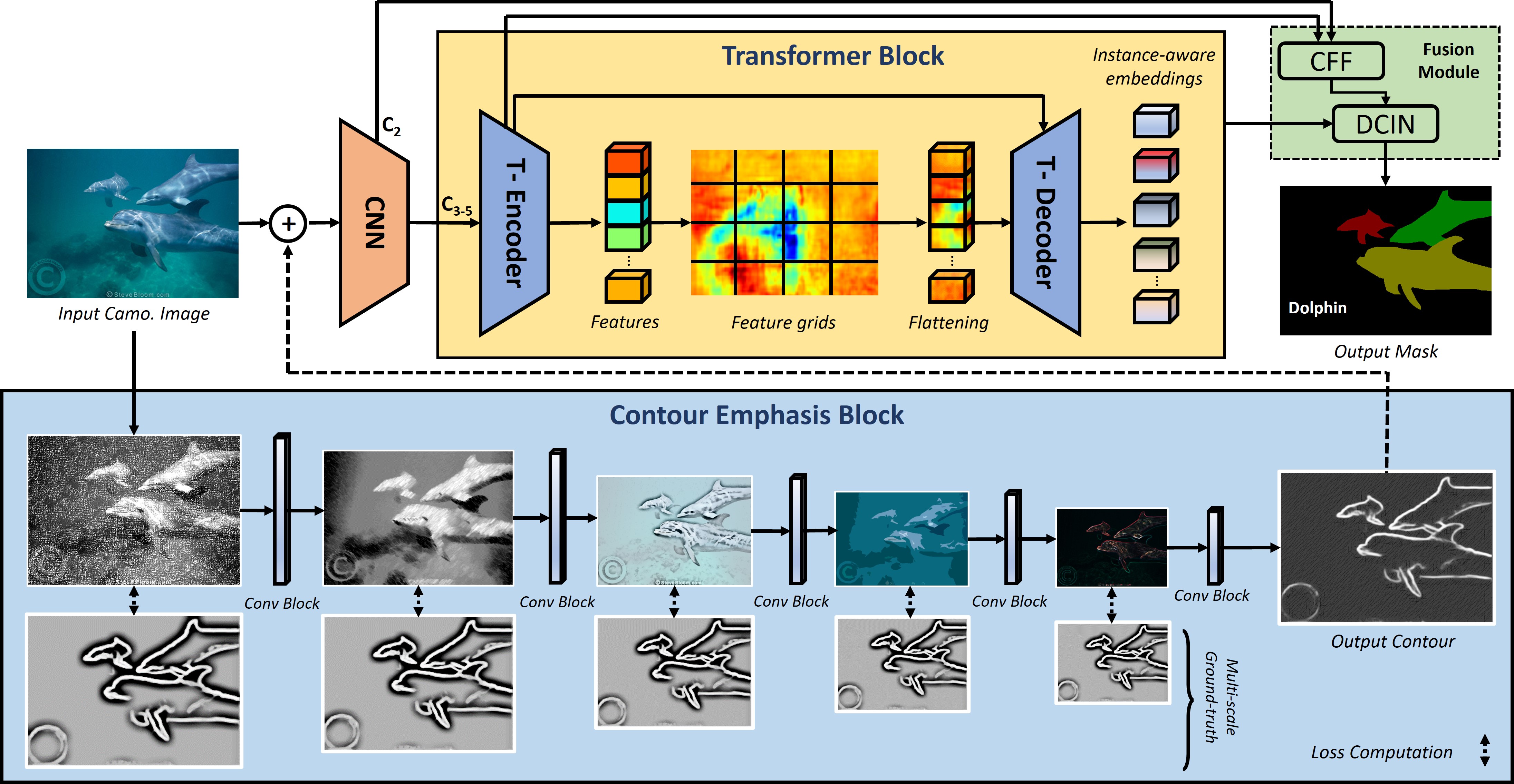
Understanding camouflage images at instance level is such a challenging task in computer vision.
Since the camouflage instances have their colors and textures similar to the background, the key to distinguish
them in the images should rely on their contours. The contours seperate the instance from the background, thus
recognizing these contours should break their camouflage mechanism. To this end, we address the problem of camouflage
instance segmentation via the Contour Emphasis approach. We improve the ability of the segmentation models by
enhancing the contours of the camouflaged instances. We propose the CE-OST framework which employs the well-known
architecture of Transformer-based models in a one-stage manner to boost the performance of camouflaged instance
segmentation. The extensive experiments prove our contributions over the state-of-the-art baselines on different
benchmarks, i.e. CAMO++, COD10K and NC4K.
Code
Poster
Presentation
Citation:
Thanh-Danh Nguyen, Duc-Tuan Luu, Vinh-Tiep Nguyen†, and Thanh Duc Ngo,
“CE-OST: Contour Emphasis for One-Stage Transformer-based Camouflage Instance Segmentation.”
2023 International Conference on Multimedia Analysis and Pattern Recognition (MAPR). IEEE, 2023. (Scopus)
[DOI,
PDF]
* indicates equal contribution, † denotes corresponding authors.